Semester Project: Adaptation of Sound Source Separation Model for Missing Cues
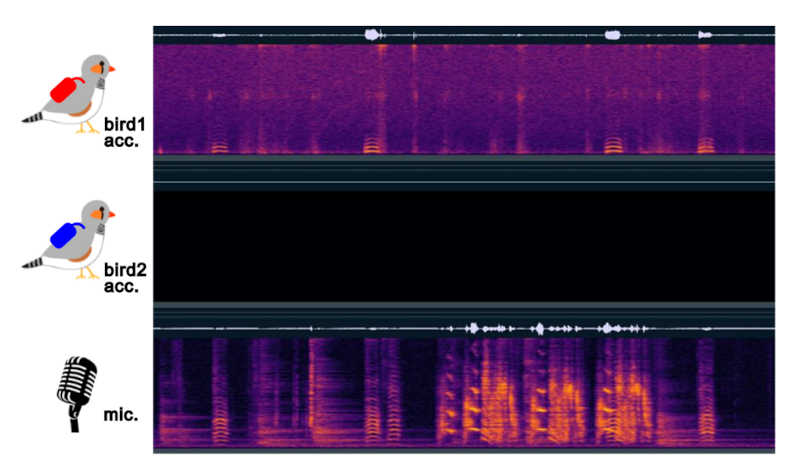
Figure 1. Example data with one missing accelerometer signal, where two birds are vocalizing simultaneously.
Background
Understanding animal social behavior, including vocal communication, requires high-quality recordings of interacting individuals. However, these recordings often contain overlapping vocalizations and background noise, making it challenging to obtain individual vocalizations. To adress this challenge, our group has developed Vib2Sound, a sound source separation system for zebra finch vocalizations [1]. This model leverages body-mounted accelerometer signals as guiding cues, recorded in a multimodal recording setup that enables naturalistic interactions among birds [2].
While the model performs well in separating overlapping vocalizations from multiple individuals, it relies heavily on the accelerometer inputs. Since the accelerometer signals are transmitted through radio, some signals may be lost due to fading (Figure 1), causing Vib2Sound to fail in reconstructing vocalizations. Therefore, adapting Vib2Sound to such recordings and making it robust to missing accelerometer inputs is a necessary next step.
One straightforward approach is to reconstruct the other bird’s vocalization than the target bird’s, and then subtract this reconstruction from the original unseparated microphone recording. More sophisticated approaches, built directly into the machine learning architecture, are actively being developed in the field of multimodal speech separation [3-5], from which we could potentially draw inspiration.
Project description
Your work will include:
-
- Exploring different methods for adapting Vib2Sound to missing accelerometer signals and evaluating the performance of each method.
-
- Annotating clean vocalization instances from multi-bird datasets for Vib2Sound training and evaluation.
Your benefits
Through this project, you will:
Your profile
We are looking for a motivated student with:
-
- A background in computer science, neuroscience, biology, or a related field.
-
- Skills in audio signal processing, programming (Python), and/or experience with machine learning.
-
- Motivation and passion for understanding animal behavior and vocal communication.
Contact
If you’re interested, please send a CV and transcripts of records to:
Supervisors: Mai Akahoshi (makahoshi@ethz.ch), Yuhang Wang (yuhang@ini.ethz.ch)
Host: Prof. Richard Hahnloser (rich@ini.ethz.ch)
Literature
-
1. Akahoshi, M., Wang, Y., Cheng, L., Zai, A. T., & Hahnloser, R. H. R. (2025). Vib2Sound: Separation of multimodal sound sources. bioRxiv. https://doi.org/10.1101/2025.05.08.652866
-
2. Rüttimann, L., Rychen, J., Tomka, T., Hörster, H., Rocha, M. D., & Hahnloser, R. H. R.
(2022). Multimodal system for recording individual-level behaviors in songbird groups. bioRxiv. https://doi.org/10.1101/2022.09.23.509166
-
3. Pan, T., Liu, J., Wang, B., Tang, J., & Wu, G. (2024). RAVSS: Robust audio-visual speech separation in multi-speaker scenarios with missing visual cues. Proceedings of the 32nd ACM International Conference on Multimedia (MM ’24), 4748–4756. https://doi.org/10.1145/3664647.3681261
-
4. Chang, O., Braga, O., Liao, H., Serdyuk, D., & Siohan, O. (2023). On robustness to missing video for audiovisual speech recognition. arXiv. https://doi.org/10.48550/arXiv.2312.10088
-
5. Makishima, N., Ihori, M., Takashima, A., Tanaka, T., Orihashi, S., & Masumura, R. (2021). Audio-visual speech separation using cross-modal correspondence loss. Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 6673–6677. https://doi.org/10.1109/ICASSP39728.2021.9413491