Reinforcement learning with spiking neural network models and chips
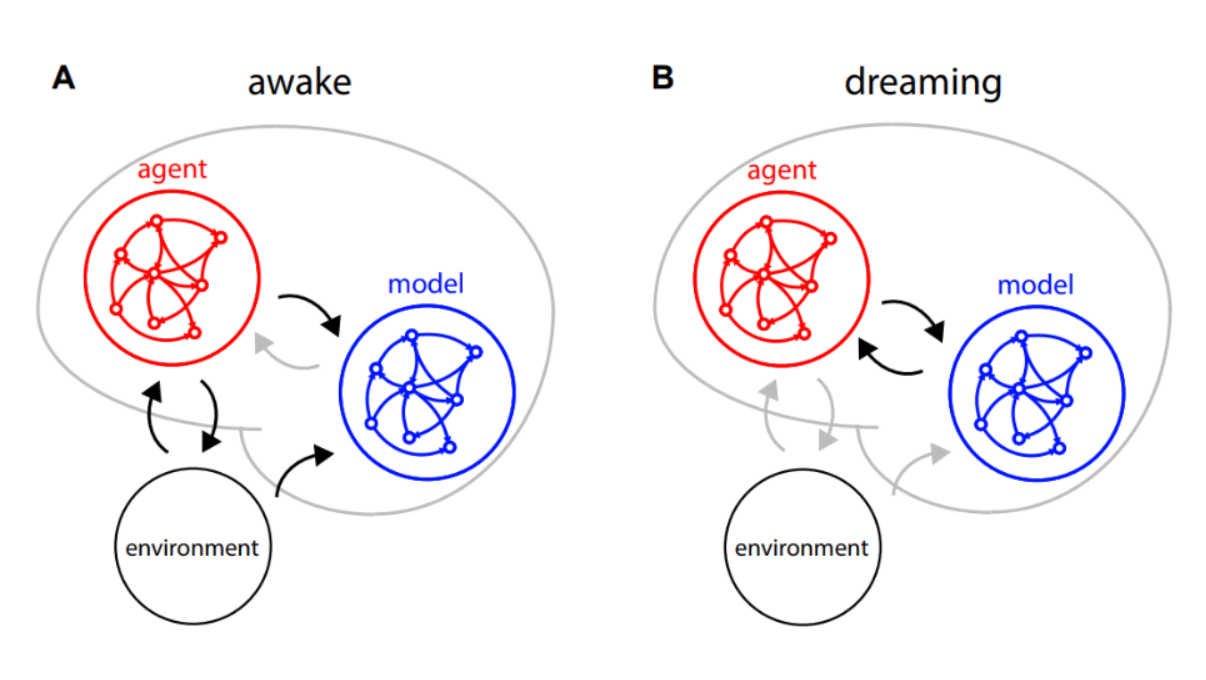 A.
A. A two-module spiking network:
the agent-network valuate the policy while the model-network predicts the following environment observations.
B. When disconnected from the environment the two networks inter act to improve the agent policy.
Supervisor: Giacomo Indiveri
Co-supervisor: Cristiano Capone
January 20, 2023
Abstract
Humans and animals can learn new skills after practicing for a few hours, while current AI-based reinforcement learning algorithms require a large amount of data to achieve good performances. A recently proposed biologically inspired model that uses spiking neural networks combined with a “wake” and a “sleep” phase learning phase shows promising results. In this project we will attempt to map this neural network onto the DYNAP-SE mixed-signal spiking neural network chip, to implement the neural dynamics in real-time, interfaced to a computer in-the-loop that will be used to implement the reinforcement-learning protocol. The goal is to validate the model and verify its robustness to biologically relevant constraints, such as limited precision, low resolution, sensitivity to noise, and in-homogeneity of neuron and synapse circuits.
Background
Model-based reinforcement learning (RL) is an approach to training AI systems in which the AI agent learns to make decisions based on a model of the environment. This model can take many forms, such as a mathematical representation, a simulation, or a neural network. One of the most significant advantages of model-based RL is that it allows the agent to make predictions about future states of the environment. This enables the agent to plan and make decisions that are more informed, and less dependent on trial and error. This ability to predict future states can lead to more efficient decision-making and faster convergence to the optimal policy. For this reason Model-based RL is generally considered to be more sample-efficient than model-free RL. This means that the agent can learn from fewer interactions with the environment.
Model-based RL can be used to generate the experiences, while a model-free method can be used to learn from them. This hybrid approach can be more sample-efficient and lead to faster convergence to an optimal policy.
The implementation of the model in sofware or on hardware would allow an agent to learn and improve its policy at a very fast time-scale, without being constrained by the physical timescale of the world. Moreover, neuromorphic hardware can perform computations in parallel across many neurons and synapses, which can be much faster than traditional digital hardware that performs computations sequentially.
Neuromorphic electronic circuits have been shown to be a promising technology for the implementation of spiking neural network models. These circuits are typically designed using mixed-mode analog/digital transistors and fabricated using standard VLSI processes to emulate the physics of real neurons and synapses in real-time.
Similar to the neural processes they model, neuromorphic systems process information using energy-efficient asynchronous, event-driven, methods. They are adaptive, fault-tolerant, and can be flexibly configured to display complex behaviors by combining multiple instances of simpler elements. The most striking difference between neuromorphic processing systems and standard computing ones is in their unconventional (beyond von Neumann) architecture: rather than implementing one or more digital, time-multiplexed, central processing units physically separated from the main memory areas, they are characterized by parallel processing with co-localized memory and computation. This fundamental architectural difference is the main reason that allows neuromorphic systems to perform bio-signal processing using orders of magnitude less power (ranging from a factor of 10× to 1000×) than any AI conventional computing system.
Project goals
The aim of the project is to project to map a two-modules spiking network onto the DYNAP-SE mixed-signal spiking neural network chip, to implement the neural dynamics in real-time.
The first step of the project is to implement on-chip a recurrent spiking network capable to learn in a supervised fashion (see [1]) the world model (the model-module). The second step is to build the agent-module that will be interfaced to a computer in-the-loop that will be used to implement the reinforcement-learning protocol.
One major goal is to validate the model and verify its robustness to biologically relevant constraints, such as limited precision, low resolution, sensitivity to noise, and in-homogeneity of neuron and synapse circuits.
Finally, this architecture will be benchmarked on standard discrete control tasks, such as the games from the Atari suite (e.g. Pong or Boxing).
Relevant literature
Links to related work:
1. The paper describing the reinformcement learning model is available at
https://arxiv.org/abs/2205.10044
2. A paper describing the general domain of spiking neural network “neuromorphic” chips is here:
https://arxiv.org/abs/1506.03264
3. The paper describing the specific SNN DYNAP-SE chip that will be used in the project is the following one:
https://arxiv.org/abs/1708.04198
4. A paper describing how to use populations of neurons to deal with noise and low precision in SNNs is:
https://www.biorxiv.org/content/10.1101/2022.10.26.513846v1
Requirements
The student is expected to have a good understanding of spiking recurrent neural networks and network
dynamics. The project will make extensive use of Python code and Jupyter notebooks. Neuromorphic hardware will be used with the computer-in-the-loop, so having experience with neuromorphic circuits is a plus (but not a requirement).